
オス!IT格闘じいじだ。
メインフレームの現場で、送られてきたデータのレイアウトを変更したり、特定の項目をひっくり返したり、空白やゼロで桁数を合わせる(パディング)なんて処理、日常茶飯事だよな。
そんなとき、わざわざCOBOLのMOVE文を並べただけのデータ変換プログラムを1本起動してねえだろうな?
その処理、すべてソートユーティリティの「INRECカード」と「OUTRECカード」だけで瞬殺できるぜ!
今回は、現場で最も多用されるBUILDを使った項目入れ替えやスペース埋め、ゼロパディング(前ゼロ詰め)の具体的な書き方はもちろん、若手が絶対に一度はやらかす「INRECを使ったことによるソートキーの位置ズレ・アベンド」の回避策までJCLサンプル付きで徹底解説する。
「INRECとOUTREC、結局どっちに何を書けばいいの?」と迷う若手から、プログラムレスで爆速データ加工を極めたいベテランまで、この記事をコピペして現場の修羅場をスマートに切り抜けてくれ!
💡 じいじの警告: 「ソート全体の流れや、基本JCLの形をまだ頭に入れてないぜ」という奴は、まずは俺の親記事である**【z/OS】プログラム不要!DFSORT/SYNCSORTでできる7大機能まとめ(JCLサンプル付き)**を先に脳細胞に叩き込んできてくれよな!
■ 基本編:『INREC / OUTREC』の違いと使い使い分けの鉄則

データを自在に変形させるこの2つのカード。名前は似ているが、「ソート処理(並び替え)のどのタイミングでデータを加工するか」が根本的に違う。
この違いを理解していないと、無駄なCPUコストを払ったり、思わぬバグを生む原因になる。まずはそれぞれの戦闘スタイル(ポジション)を具体的なサンプルで脳内にデプロイしてくれ。
🔄 処理の流れる順番とJCLの基本形
メインフレーム内部では、データは以下の順番でリング(処理)を通過する。まずはこの「位置関係」を SYSINのサンプルで掴んでくれ。
//SYSIN DD *
INREC FIELDS=(1,80) * 🥊 ① ソートをかける「前」に加工
SORT FIELDS=(1,5,CH,A)
OUTREC FIELDS=(1,80) * 🥊 ② ソートが終わった「後」に加工
/*- SORTIN(入力ファイルの読み込み)
- 🥊 INREC:ソートエンジンにデータが渡る前に、あらかじめデータを加工する。
- ⚙️ SORT / MERGE:並び替え処理を実行。
- 🥊 OUTREC:ソートがすべて終わった後、ファイルに出くわす直前に最終加工する。
- SORTOUT(出力ファイルへの書き出し)
🥊 格闘じいじの使い分け鉄則(超具体例付き)
「どっちに書いても同じ結果になるなら、どっちでもいいじゃん」と思った奴、甘いぜ!ガードがガラ空きだ。現場では以下の具体的シチュエーションで明確に使い分ける。
①『INREC』を使うべき場面:ソートの処理効率(スピード)を爆上げしたいとき
例えば、元のデータ(SORTIN)が「1レコード:1,000バイト」もある巨大なファイルだったとする。だけど、実際にソートで使いたいキーは「先頭の5バイト(社員番号)」だけで、最終的に出力したいデータも「先頭から50バイト分だけ」だったとするよな。
このとき、INRECを使わずに1,000バイトのままソートに放り込むと、ソートエンジンは無駄な950バイト分も一緒に抱えて並び替えのステップを踏むことになる。これじゃあワークファイル(SORTWK)の容量も食うし、処理も重くなる。
そこで、ソートをかける前にINRECで必要な50バイトだけをギュッと引っこ抜くんだ!
* 【INRECの具体例】
* 入力1,000バイトのファイルから、必要な50バイトだけをソート前に引っこ抜く
//SYSIN DD *
INREC FIELDS=(1,50)
SORT FIELDS=(1,5,CH,A)
/*効果: ソートエンジンに渡る時点でデータが50バイトに縮小されているため、処理速度が爆速になり、システム全体のCPUコストを大幅に削減できる。 これがプロの防衛策だ。
②『OUTREC』を使うべき場面:最後の出力用にレイアウトを綺麗に整えたいとき
逆に、ソートや重複削除(SUM)の処理自体は「元のデータレイアウトのまま」安全に行い、最後の最後、ファイル(SORTOUT)に書き出す直前で、他システムへ送るために形をトランスフォームさせたい場合は、OUTRECの出番だ。
* 【OUTRECの具体例】
* 元のレイアウト(80バイト)でソートし、出力の直前で項目をひっくり返す
//SYSIN DD *
SORT FIELDS=(1,5,CH,A)
OUTREC FIELDS=(6,10,1,5,11,70) * 6〜15バイト目を先頭に、1〜5バイト目を後ろに入れ替え
/*効果: ソート処理そのものは元のカラム位置で安全に実行されるため、キーの位置計算で混乱するリスクを減らせる。最後の出力だけをスマートに変形させたいときの鉄板スタイルだぜ!
■ 実践編:『BUILD』を使ったデータの入れ替えとパディング(埋め処理)

ここからは、現場で最も多用される具体的なレイアウト加工テクニックを伝授する。
INRECでもOUTRECでも、データを再構築するときは BUILD(または FIELDS)というキーワードに続けて、新しい配置を指定していく。
【コピペ用】現場で一番使うデータ変形・パディングサンプル
//SYSIN DD *
SORT FIELDS=(1,5,CH,A)
OUTREC BUILD=(11,20, * ① 11〜30バイト目を先頭に持ってくる
1,10, * ② 元の先頭10バイトをその後に繋ぐ
10X, * ③ 後ろに10バイト分のスペース(空白)を埋める
5Z) * ④ 最後に5バイト分のゼロ(C'00000')をパディングする
/*🥊 格闘じいじのテクニカル解説
上のサンプルコードで叩き込んでいるコンボの正体はこれだ!
11,20 と 1,10(項目の入れ替え):
元のデータから指定した「位置, 長さ」の項目を引っこ抜き、書いた順番通りに左からギュッと詰め込んで再配置する。
10X(空白・スペース埋め):
長さX と書くことで、指定した長さ分のスペース(X’40’)を自動的に挿入してくれる。文字項目の桁数合わせや、将来用の予備領域(リザーブエリア)を確保したいときに一撃で使える便利技だ。
5Z(ゼロパディング・前ゼロ詰め):
長さZ と書くと、指定した長さ分の文字としてのゼロ(C’0′ / X’F0’)を自動的に埋めてくれる。 金額や数量などの数値項目で、「8桁固定にするために足りない前方の桁をゼロで埋めたい」というパディング要件の時に大活躍するぜ!
■ 現場の罠:レイアウト変更による「ソートキー位置ズレ」のアベンド
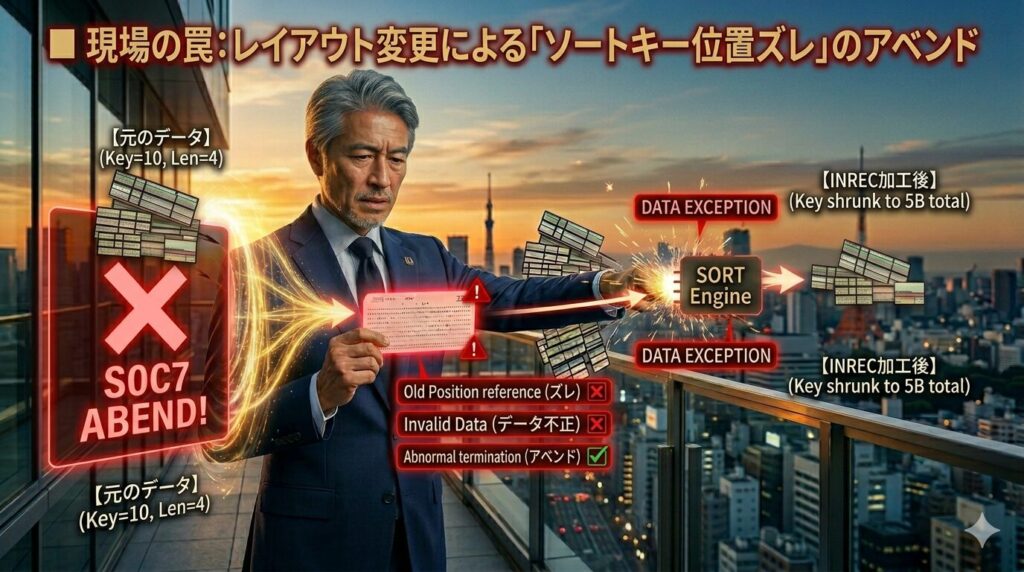
さあ、今回も27年のキャリアから、若手が100%一度は涙を流す致命的なカウンターパンチ(罠)について警告しておく。
それは、**「INRECでデータレイアウトを縮小した後に、SORTカードを書くときの位置計算ミス」**だ。
🚨 なぜ位置ズレでアベンドが起きるのか?(原因)
基本編で解説した通り、処理の順番は INREC が先で、SORT が後だ。
例えば、元の入力ファイル(SORTIN)のレイアウトが「10バイト目が商品コード(キー)」「20バイト目が金額」だったとするよな。
ここで、INRECを使って「20バイト目の金額」だけを先頭に引っこ抜く加工をしたとする。
* 【アベンドする危険な例】
INREC FIELDS=(20,5) * 🥊 20バイト目からの5バイト(金額)だけを切り出した!
SORT FIELDS=(10,4,CH,A) * 🚨 ガラ空き!ここでジョブがアベンドする!お分かりだろうか?INRECを通った時点で、データは「20バイト目からあった金額データの5バイト分」しか存在しない。元々10バイト目にあった商品コードなんて、ソートエンジンに届く前にもうゴミ箱に捨てられて存在しないんだ!
それなのに、SORTカードで元のレイアウトの感覚のまま「10バイト目から4バイト分をキーにしてソートせよ」なんて命令を出すから、ソートユーティリティは「指定されたカラムがデータ内に存在しねえぞ!」と怒り狂い、構文エラーや位置不正でジョブを容赦なく叩き落とす(アベンド)んだ。
🛠️ 格闘じいじ直伝:位置ズレを防ぐ防衛策
INRECを使うときは、「ソートキーも含めて切り出すこと」、精度高くSORTカードには「INREC加工“後”の新しいカラム位置を指定すること」が絶対条件だ!
* 【大正解のガードスタイル】
//SYSIN DD *
INREC FIELDS=(10,4,20,5) * ① 商品コード(4B)と金額(5B)を並べて切り出す
SORT FIELDS=(1,4,CH,A) * ② 新レイアウトの1バイト目になった商品コードでソート!
/*この計算さえ間違えなければ、位置ズレのカウンターを食らうことは100%ない。INRECを使う時は、常に「今のデータの形はどうなっているか」のガードを意識しろよ!
💡 コラム:DFSORTとSyncsortって何が違うの?

ブログの中で当たり前のように DFSORT/SYNCSORT って並べて書いているけど、「そもそもSyncsort(シンクソート)って何者?」って若手に聞かれたら、こう答えてやってくれ。
「IBM純正のソートツール(DFSORT)のライバルであり、現場でめちゃくちゃシェアを持っている互換製品(サードパーティ製ツール)だぜ!」
メインフレームのソートの世界は、実質この2大巨頭がリングを支配しているんだ。
| 項目 | DFSORT(ディーエフソート) | Syncsort(シンクソート) |
|---|---|---|
| 開発元 | IBM純正 | Syncsort社(現:Precisely社) |
| 特徴 | OS(z/OS)に標準で組み込まれている王道ツール。 | 処理速度がとにかく速い。 |
| 互換性 | 基準となる標準仕様。 | DFSORTのカード(SYSIN)がそのまま動く完全互換。 |
昔の日本のメインフレームの現場(特に大規模な金融や製造業のバッチ処理)では、「ソートの処理時間を1分でも短縮して、夜間バッチを朝までに終わらせる」のが至上命題だった。そこで、「IBMのDFSORTより、Syncsortを入れたほうがCPUの効率が良いし爆速だぜ!」ってことで、多くの現場でエースとして採用されてきたんだ。
■ まとめ:レイアウトを支配する者が、バチバチのバッチ処理を制す

一社のお見送りや面接のミスマッチで凹んでいる暇があったら、このINREC/OUTRECを1行でも多く組んで、プログラムレスでデータを自在にトランスフォームさせる「テクニカルな武器」を研ぎ澄まそうぜ。
COBOLで何何十行もMOVE文を書くより、ソートカードのBUILD、X、Zを数行パパッと組み合わせる方が、遥かにスマートで、処理速度も速く、100%裏切らない最強のカウンターパンチになってくれる。
次回は、別々のファイルをJCLだけでガッチャンコと結合させる達人技、「JOINKEYSの極意」をリアルな実例付きで深掘りしていくぜ!
次戦に向けて、スキルもシステムも自動化(最適化)していこうぜ。
Status: Batch Processing (次戦のJCL投入準備完了だ!)
関連記事:




コメント